




Wraz z tegoroczną premierą linii iPhone Xs oraz iPhone Xr, Apple zaprezentowało napędzający je układ A12 Bionic. Od tego wydarzenia minęło już kilka miesięcy, które pozwoliły badaczom bliżej poznać szczegóły konstrukcji układu oraz wprowadzone przez Apple zmiany do własnej architektury. Apple A12 Bionic nie jest rewolucją w zakresie wydajności – jest jednak kolejnym znaczącym krokiem w rozwoju najwydajniejszych na rynku mobilnych układów System-On-Chip.
Pierwszy komercyjny układ w litografii 7 nm
Proces litograficzny ma bardzo duże znaczenie w konstrukcji dowolnego procesora, w szczególności wtedy, gdy trafić ma on do niewielkich, mobilnych urządzeń. Zmniejszenie litografii przekłada się na możliwość umieszczenia większej ilości półprzewodników na identycznej powierzchni lub znaczące zmniejszenie wymiarów płytki krzemowej przy zastosowaniu identycznej ilości półprzewodników. Ma także spory wpływ na energooszczędność całego układu. Obie te cechy (wielkość, energooszczędność) są bardzo ważne w szczególności w konstrukcji mobilnych SoC – tam, gdzie ilość miejsca oraz pojemność akumulatora jest ograniczona.
Dlatego też w przypadku Apple A12 Bionic producent zdecydował się na zastosowanie najnowszego procesu 7 nm FinFET od tajwańskiej firmy TSMC. Czyni to A12 Bionic pierwszym komercyjnym układem w litografii 7 nm na rynku. Skąd to podkreślanie słowa “komercyjny”? Wszystkiemu jest winien Huawei, a dokładniej jego spółka-córka HiSilicon, która dosłownie chwilę przed planowaną premierą nowych iPhone przedstawiła swój najnowszy układ o nazwie Kirin 980 również wykonany w litografii 7 nm. Układ ten trafił jednak do pierwszych urządzeń (takich, jak Huawei Mate 20 Pro) później, niż A12 Bionic.
Co w krzemie piszczy?

Pod względem samej konstrukcji, którą widać na powyższym prześwietleniu, Apple A12 Bionic niewiele różni się od swojego poprzednika, czyli A11 Bionic. Sam rozmiar płytki krzemowej uległ jednak znaczącemu zmniejszeniu dzięki przejściu z litografii 10 nm na 7 nm i to pomimo ogromnego zwiększenia się liczby tranzystorów – z 4,3 mld do 6,9 mld. Rozmiar całego układu Apple A12 wynosi 83,27 milimetrów kwadratowych – o 4,39 mm2 mniej od poprzednika. Opisywany układ jest fizycznie najmniejszym SoC w historii całej serii Apple Ax.
2 + 4 = 6
Przechodząc do konstrukcji procesora, jest on układem sześciordzeniowym złożonym z dwóch rdzeni wydajnych (big) oraz czterech rdzeni energooszczędnych (LITTLE). W przeciwieństwie do dwuletniego już A10 Fusion, mogą one pracować jednocześnie dzięki technologii big.LITTLE HMP opisanej szczegółowo w tym artykule. Mówiąc bardziej ogólnie, całe założenie big.LITTLE polega na połączeniu różnych rodzajów rdzeni w jednym układzie. Duże rdzenie zapewniają wysoką wydajność, ale potrzebują do działania dużych ilości energii. Małe rdzenie natomiast oferują niższą wydajność, ale mogą zadowolić się mniejszymi porcjami cennego prądu z akumulatora. Dzięki big.LITTLE możliwe jest delegowanie zadań do poszczególnych grup rdzeni zależnie od złożoności i priorytetu danego zadania. Zajmuje się tym programowy scheduler. Skrót HMP odnosi się do heterogeneous multiprocessing – rozwinięcia technologii big.LITTLE, w którym możliwe jest działanie jednocześnie różnych rdzeni – przykładowo trzy energooszczędne i jeden wydajny lub dwa wydajne i jeden energooszczędny. Pozwala to jeszcze bardziej ograniczyć zużycie energii elektrycznej w mobilnych SoC dzięki precyzyjnemu przydzielaniu zadań i przełączaniu aktywnych rdzeni.
Rdzenie wydajne – Vortex
Wydajne rdzenie (big) w przypadku Apple A12 Bionic noszą miano Vortex. Układ zawiera w sobie dwa takie rdzenie, a ich maksymalne taktowanie wynosi 2,5 GHz. Osiągnięcie tego poziomu możliwe jest jednak tylko wtedy, gdy jeden rdzeń Vortex jest aktywny – gdy do pracy zostaje zaprzęgnięty drugi, taktowanie spada do 2380 MHz. Aktywność czterech rdzeni energooszczędnych nie ma wpływu na taktowanie rdzeni dużych – w przeciwieństwie do poprzednika, A11 Fusion, w którym taktowanie mogło być w takiej sytuacji zaniżone do 2083 MHz w początkowych 2380 MHz.
O ile wzrost częstotliwości wynosi jedynie 5%, to gruntownej reorganizacji uległ podsystem pamięci cache. Opóźnienia w dostępie do cache poziomu drugiego (L2) zostały zredukowane aż o 29%. Sama ilość pamięci L2 nie uległa zmianie i wciąż wynosi 8 MB, przy czym pojedynczy wątek może zająć do 6 MB. Ilość pamięci poziomu pierwszego (L1) została natomiast zwiększona aż dwukrotnie – z 64 KB do 128 KB.

Podobnie, jak w przypadku poprzedników, klaster dużych rdzeni Apple A12 Bionic oferuje ogromną wydajność jednowątkową. Zaawansowane wejście, przetwarzanie i wyjście danych z rdzenia, przetwarzanie aż sześciu instrukcji jednocześnie, rozbudowane mechanizmy przetwarzania poza kolejnością oraz obsługi pamięci podręcznej przekładają się na wydajność niebezpiecznie zbliżającą się lub wręcz dościgającą architekturę Intel Core – lidera układów desktopowych. Oczywiście, implementacja zmodyfikowanej przez Apple architektury ARM w obudowach iPhone nie pozwala jej rozwinąć pełni wydajności z uwagi na ograniczenia termalne i konieczność kładzenia szczególnego nacisku na energooszczędność.
W porównaniu do swojego bezpośredniego poprzednika – rdzeni Monsoon z A11 – Vortex przynosi 15% wzrost ogólnej wydajności oraz 40% mniejsze zużycie energii. Pierwsze osiągane jest głównie poprzez zmiany w cache oraz lekkie podniesienie taktowania, drugie zaś poprzez zmianę procesu litograficznego z 10 na 7 nm. Tak przynajmniej mówią dane Apple. W rzeczywistości okazuje się, że są one dość zachowawcze, szczególnie w zakresie wzrostu wydajności – w niektórych zadaniach kładących szczególny nacisk na wykorzystanie pamięci podręcznej wzrosty potrafią być znacznie wyższe.
Rdzenie energooszczędne – Tempest
W przypadku klastra czterech rdzeni energooszczędnych umieszczonych w układzie A12 Bionic, Apple wspomina jedynie o 50% mniejszym zużyciu energii. Oznaczałoby to, że rdzenie nie przeszły żadnych znaczących zmian w zakresie wydajności obliczeniowej wynikającej z samej budowy rdzenia. Co ciekawe, częstotliwość taktowania została wręcz zmniejszona w porównaniu do poprzedników, czyli rdzeni Mistral z A11. Wynosi teraz maksymalnie 1587 MHz, zamiast 1694 MHz. Ilość pamięci L1 pozostała taka sama (32 KB), ale jakby w ramach rekompensaty za mniejszą częstotliwość dodano pamięci L2 – teraz jest to 2 MB, dwa razy więcej, niż w poprzedniku.
Architektura energooszczędnych rdzeni Tempest może nie wydawać się szczególnie interesująca. Ot, mało wydajne rdzenie, które mają przede wszystkim przetwarzać niewymagające zadania. Po przyjrzeniu się ich architekturze wyłania się jednak nieco inny obraz.
Przede wszystkim, zastosowane w Apple A12 Bionic energooszczędne rdzenie Tempest obsługują wykonywanie zadań poza kolejnością. Już samo to czyni je bliższymi dużym rdzeniom konkurencji, niż tym energooszczędnym – takim, jak niezwykle popularny Cortex-A53, czy jego następca w postaci Cortexa-A55. Obsługa wykonywania zadań poza kolejnością (OoOE) znacząco zwiększa wydajność rdzenia, ale również jego skomplikowanie i apetyt na prąd. Pod względem konstrukcji, Tempest przypomina nieco 32-bitowe rdzenie Swift zastosowane w układzie Apple A6 sprzed kilku lat. Znajdziemy tu obsługę trzech instrukcji jednocześnie (w dużych rdzeniach Vortex – 6) i to w niepełnym zakresie. W większości przypadków kończy się na dwóch, a przy mieszaniu liczb stałoprzecinkowych ze zmiennoprzecinkowymi śmiało można powiedzieć, że Tempest wykonuje 1,5 instrukcji na cykl zegara.
Na jaką wydajność przekłada się to wszystko? W przypadku benchmarków wykonujących operacje na liczbach stałoprzecinkowych, przykładowo SPECinit, rdzeń Tempest z taktowaniem niespełna 1,6 GHz potrafi zrównać się z dużym rdzeniem od ARM w postaci Cortexa-A73 przy taktowaniu 2,1 GHz! Dokładnie taki rdzeń służył do wykonywania najtrudniejszych zadań we flagowcach sprzed dwóch lat, czy nawet w zeszłorocznym Kirinie 970 zastosowanym m.in. w Huaweiu P20 Pro. Przy liczbach zmiennoprzecinkowych nie jest jednak tak różowo z uwagi na brak dedykowanych jednostek wykonawczych.
Pamiętajmy jednak, że głównym zadaniem rdzeni Tempest w Apple A12 Bionic jest zapewnienie energooszczędności poprzez wyręczanie dużych rdzeni przy mniej wymagających zadaniach. Ich wydajność i tak jest bardzo duża, jak na tę rolę. Mówimy tu przecież o dwu- lub nawet trzykrotności wydajności popularnych rdzeni ARM Cortex-A53 / Cortex-A55, które znaleźć możemy we właściwie wszystkich flagowych urządzeniach z Androidem na pokładzie.
Układ graficzny Apple A12 Bionic
Wraz z premierą poprzednika w postaci A11 Bionic, Apple postanowiło porzucić stosowane w iPhone od zarania dziejów rozwiązania Imagination Technologies, by rozpocząć tworzenie własnych układów graficznych. Zastosowany w A11 układ przypominał jednak dość mocno architekturę Rogue od wspomnianej firmy. Nie porzucono nawet stosowania własnościowego rozwiązania PowerVR Texture Compression, a wprowadzone w architekturze zmiany polegały głównie na reorganizacji ułożenia elementów. Śmiało możemy mówić więc, że GPU z A11 Bionic to bardziej zmodyfikowane Rogue, niż stworzona od zera architektura.

Jak wygląda sytuacja w przypadku następcy? Przede wszystkim, Apple mówi o aż 50% wzroście wydajności. Główną zmianą jest zastosowanie kompresji pamięci, która ma bardzo duży wpływ na wydajność całego układu. Sam układ został zaś rozbudowany w najprostszy możliwy sposób czyli poprzez dołożenie jednostek wykonawczych. Apple grupuje jednostki wykonawcze nazywając je rdzeniami GPU i podając ich ilość – w przypadku A11 było to trzy, teraz zaś cztery. Taktowanie całości oceniane jest na okolice 1100 MHz.
Śmiało możemy założyć, że obiecywane 50% wzrostu wydajności jest uzyskiwane poprzez zwiększenie ilości jednostek wykonawczych o 1/3 oraz dodanie wspomnianej kompresji pamięci. Inżynierowie Apple najprawdopodobniej dopiero pracują nad pierwszą, zupełnie własnościową architekturą GPU. Słowo “najprawdopodobniej” jest bardzo często używane w przypadku GPU Apple, ponieważ firma wystrzega się od podawania jakichkolwiek znaczących danych na temat tych konstrukcji. Być może obawiają się pozwu o patenty ze strony Imagination Technologies, które niemalże w całości opierało swój biznes na sprzedaży układów graficznych dla Apple.
Słowo klucz – Bionic
AI, sztuczna inteligencja, uczenie maszynowe… To chyba najbardziej nadużywane hasła marketingowe w ostatnim czasie. O ile jednak nazywanie dzisiejszych algorytmów sztuczną inteligencją jest nazywaniem hulajnogi samochodem, tak uczenie maszynowe i odpowiedzialne za nie układy NPU poczyniły znaczący postęp i mają bardzo ważny wpływ na działanie dzisiejszych smartfonów.
Czym właściwie jest NPU? Skrót można rozwinąć w Neural Processing Unit. Inaczej mówiąc – koprocesor, w którym zintegrowano układ sieci neuronowej. Układy takie coraz częściej trafiają do flagowych SoC, w przypadku Apple pierwsze NPU zastosowano w zeszłorocznym A11 Bionic. Jego zadaniem jest wykonywanie zadań maszynowego uczenia się i przetwarzania danych. W tej roli sprawdza się on znacznie lepiej, niż zastosowanie GPU do obliczeń. Rośnie (i to wielokrotnie) nie tylko wydajność, lecz także energooszczędność – dedykowany układ zawsze wykonuje zadania sprawniej od układu ogólnego zastosowania.
W zadaniach związanych z uczeniem maszynowym, nowe NPU zapewnia od 4-krotności, do 6,5-krotności wydajności poprzednika. Przekłada się to na wydajność na poziomie 5 TFLOPS czyli 5 bilionów operacji na sekundę. Tak, bilionów – ze względu na różnice pomiędzy stosowaną w krajach europejskich długą skalą, a anglosaską krótką skalą, wiele redakcji bezwiednie przepisywało informacje o trylionach operacji na sekundę.
Koprocesory
Podobnie, jak we właściwie wszystkich nowoczesnych układach SoC, także w Apple A12 Bionic znajdziemy wiele dedykowanych jednostek wykonawczych.
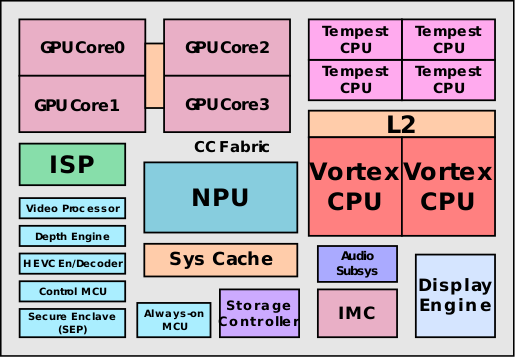
- Układ ISP – jego zadaniem jest przetwarzanie obrazu z kamer.
- Enkoder i dekoder wideo.
- Depth Engine – odpowiada za przetwarzanie informacji z kamery TrueDepth wykorzystywanej przy rozpoznawaniu twarzy FaceID
- Koprocesor M12 – przetwarza informacje pochodzące z czujników ruchu.
- Secure Enclave – przechowywane są tu klucze i hasła oraz inne dane wymagające szczególnego bezpieczeństwa. To właśnie tutaj przechowywane są nasze odciski palców TouchID, czy obrazy twarzy FaceID.
Wszystkie elementy układu, w tym procesor, układ graficzny, NPU i inne koprocesory komunikują się za pomocą tzw. system cache – pamięci podręcznej trzeciego poziomu. Jej ilość w przypadku A12 Bionic ustalono na 8 MB, dwa razy więcej, niż w poprzedniku. Wykorzystanie system cache ma także wpływ na energooszczędność – magazynowanie i przekazywanie danych z jej użyciem wymaga mniejszej ilości energii, niż gdyby wykorzystana została w tym celu pamięć RAM.
Apple A12 Bionic – podsumowanie
Najnowszy, zastosowany w iPhone Xs oraz Xr, układ Apple nie jest rewolucją w zakresie wydajności. Bez wątpienia jest jednak kolejnym znaczącym krokiem naprzód wykonanym przez inżynierów firmy. Założona przez Steve’a Jobsa, Steve’a Wozniaka oraz Ronalda Wayne’a firma może sobie na to pozwolić – jej przewaga nad konkurencją w postaci Qualcomma, Samsunga, czy HiSilicon w dziedzinie wydajności i zaawansowania architektury jest dziś ogromna.

W Geekbenchu, benchmarku sprawdzającym wydajność procesora, Apple A12 Bionic pokonuje z łatwością swoją tegoroczną konkurencję. Snapdragon 845 osiąga w teście wielu rdzeni około 8350 punktów, Exynos 9810 – od 8500 do 8900 punktów. W benchmarkach graficznych sytuacja jest bardzo podobna, tu jednak ogromne znaczenie ma wykorzystywane przez Apple API Metal. Dopiero następcy wymienionej konkurencji czyli Snapdragon 855 oraz Exynos 9820 najprawdopodobniej dogonią wydajność A12, pół roku po jego premierze będąc układami następnej generacji.
Po co to wszystko?
Wielu może powiedzieć, że ta ciągła walka o wzrost wydajności jest bezzasadna. Że smartfony dziś są już wystarczająco wydajne. Nie zgodzę się. Narzekanie tego typu mogliśmy usłyszeć pięć lat temu. Czy komukolwiek sprawia dziś przyjemność użytkowanie pięcioletniego smartfona? Dodatkowo, smartfon z nadwyżką wydajności pozwoli nam cieszyć się szybkim działaniem przez dłuższy okres czasu, niż ten, który dziś do wszystkiego starcza. Aplikacje rosną, systemy operacyjne stają się coraz bardziej funkcjonalne, a przez to coraz cięższe. Wydajność SoC pozostaje natomiast zawsze taka sama.
Przede wszystkim jednak, i jestem tego całkowicie pewien, Apple nie rozwija swojej architektury z myślą o iPhone. Głównym celem jest uczynienie z iPada prawdziwie pro-urządzenia, które podoła wymagającym aplikacjom, takim jak nadchodzący pełny Photoshop oraz zastąpienie Intela swoimi własnymi układami w komputerach Mac. Już dziś wydajność układów linii Ax byłaby wystarczająca po podniesieniu zegarów. Własny komputer, z własnym systemem operacyjnym, działającym na własnym procesorze. To takie, chciałoby się powiedzieć, Apple’owskie.